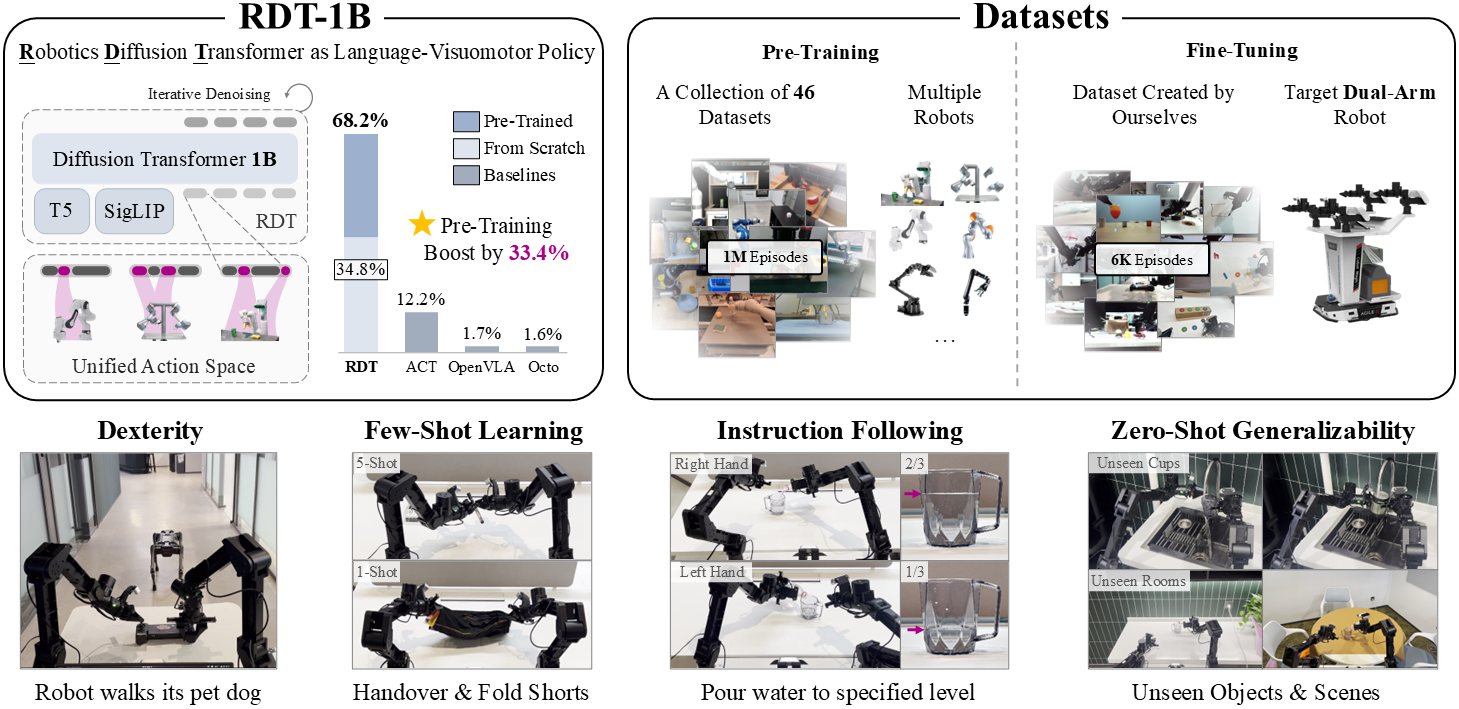
We present Robotics Diffusion Transformer with 1.2B parameters (RDT-1B), the largest diffusion-based foundation model for robotic manipulation. It is pre-trained on the largest multi-robot collection of 46 datasets with 1M+ episodes. To boost its bimanual capability, we have collected 6K+ episodes (one of the largest to date) on the ALOHA dual-arm robot for fine-tuning. It has set a new benchmark in terms of dexterity, zero-shot generalizability, and few-shot learning. It supports control of almost all modern manipulators (e.g., dual-arm, joints, EEFs, and even wheeled locomotion) and is ready for the community to fine-tune with their robots🚀!
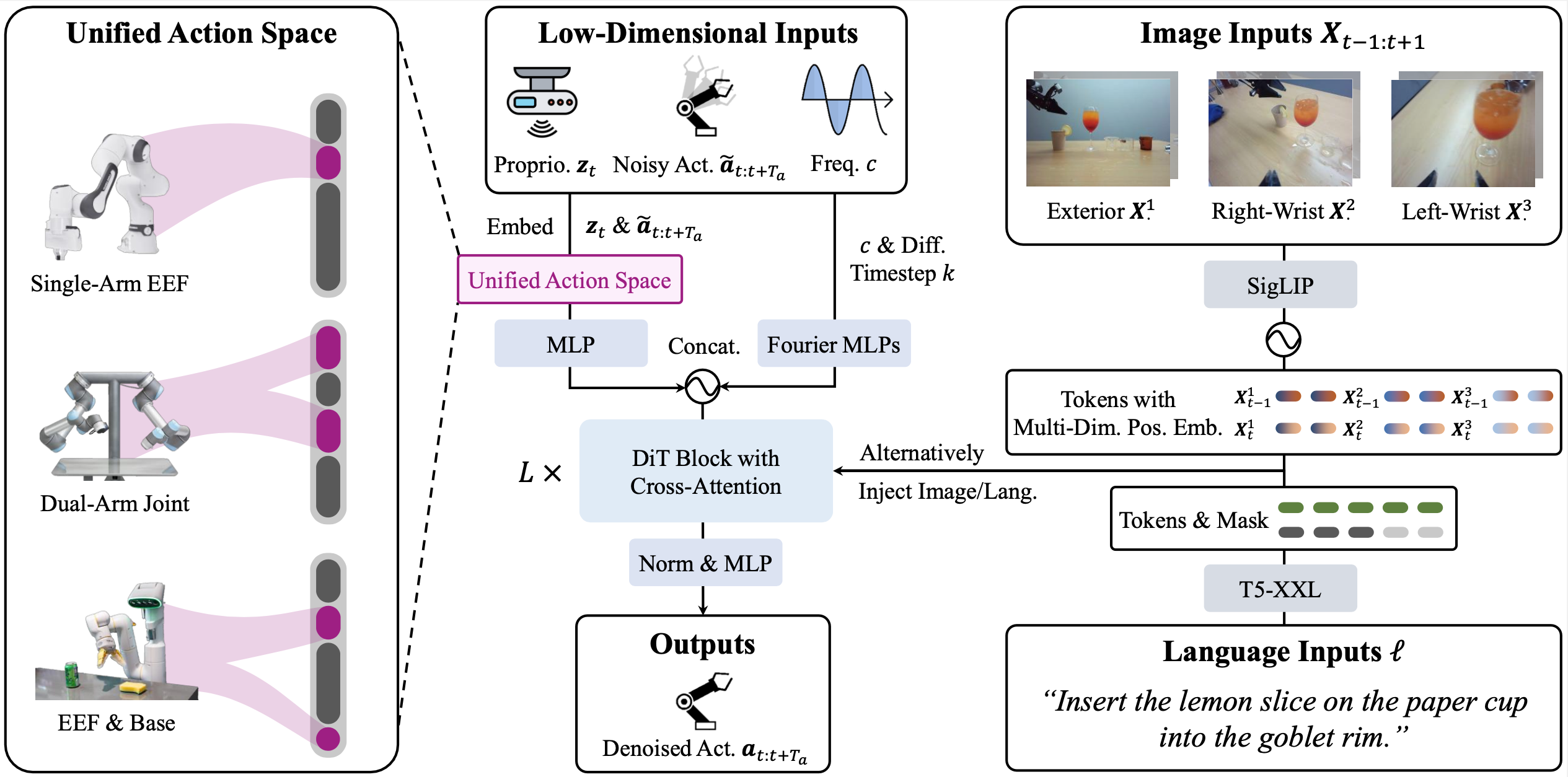
Heterogeneous action spaces of various robots are embedded into a unified action space for cross-robot model training. Inputs: low-dimensional proprioception zt, noisy action chunk ãt:t+Ta, control frequency c, and diffusion timestep k, acting as denoising inputs; image and language inputs, acting as conditions. Outputs: denoised action chunk at:t+Ta.
The following videos show that RDT can perform dexterous manipulation tasks. In the sample task, it must push the joystick straight enough to move the robot dog straight forward. Even the slightest push angle may cause the robot dog to deviate.
The following videos show that RDT can zero-shot generalize to unseen objects.

The following videos show that RDT can stick to provided instructions and zero-shot generalize to unseen modalities. RDT is required to pour water into the cup so that the water level is exactly the same as the specified level, 1/3 or 2/3. Note that RDT has only seen the instructions for water levels of little, half, and full in the training data, while 1/3 and 2/3 are unseen.


Resulting water levels in 8 trails. Left: pouring water with the left hand, specifying the water level as one-third; Right: pouring water with the right hand, specifying the water level as two-thirds.
The following videos show that RDT can zero-shot generalize to unseen scenes.
The following videos show that RDT can learn new skills with 1-5 demonstrations. A skill refers to verbs like "wipe" and "open".
In the experiment, we deliberately limited the movement speed of the robot arm to ensure safety and reduce wear. In fact, the inference frequency of RDT (6 action chunks/sec or 381 actions/sec) can fully support the robot arm to reach a speed comparable to human operators. The following are inference videos without the speed limit of the robot arm.
We benchmark our pre-trained RDT model (RDT (ours)) against baselines including RDT without pre-training (RDT (scratch)), OpenVLA, ACT, and Octo.
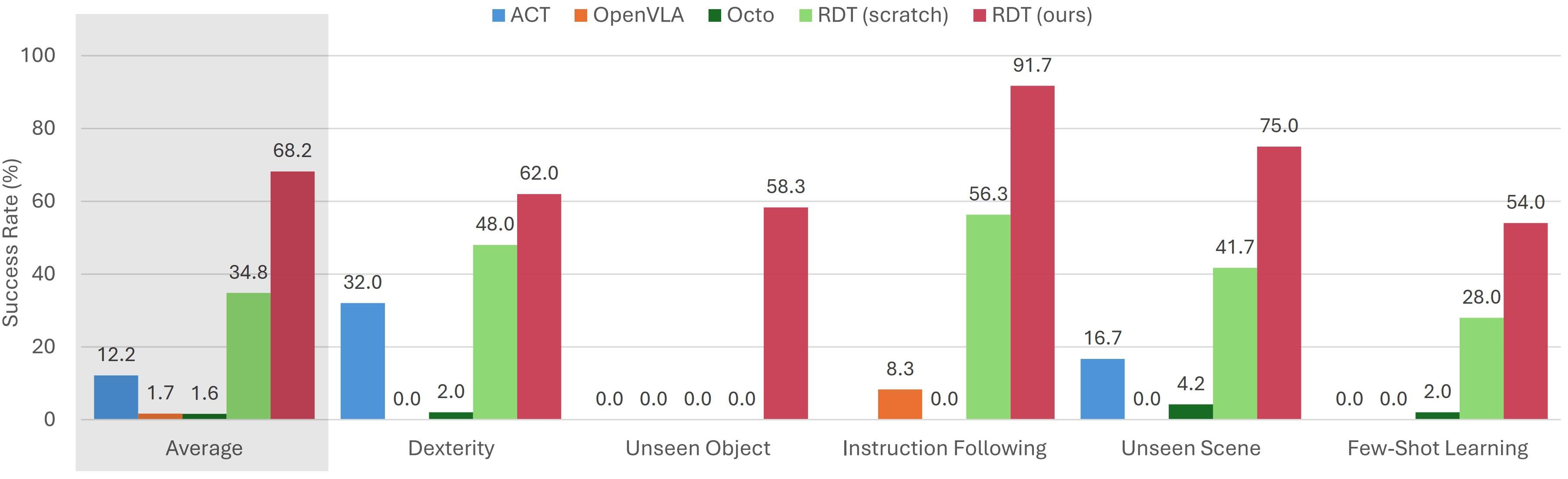
Here are some sample comparative videos:
⚠️ACT
(wrong direction)
❌OpenVLA
(grab failed)
⚠️RDT (scratch)
(not straight)
✅RDT (ours)
(straight route)
⚠️OpenVLA
(pour failed)
❌Octo
(grab failed)
⚠️RDT (scratch)
(wrong water level)
✅RDT (ours)
(correct water level)
❌ACT
(grab failed)
⚠️Octo
(pour failed)
❌RDT (scratch)
(grab failed)
✅RDT (ours)
(pour success)
❌ACT
(grab failed)
❌OpenVLA
(grab failed)
❌RDT (scratch)
(fold failed)
✅RDT (ours)
(fold success)
We use the following videos to demonstrate the robustness and repeatability of RDT. It can complete various tasks 5-8 times repeatedly without any failure.
We conduct ablation studies on various components of RDT to understand their importance. We consider the variants of:
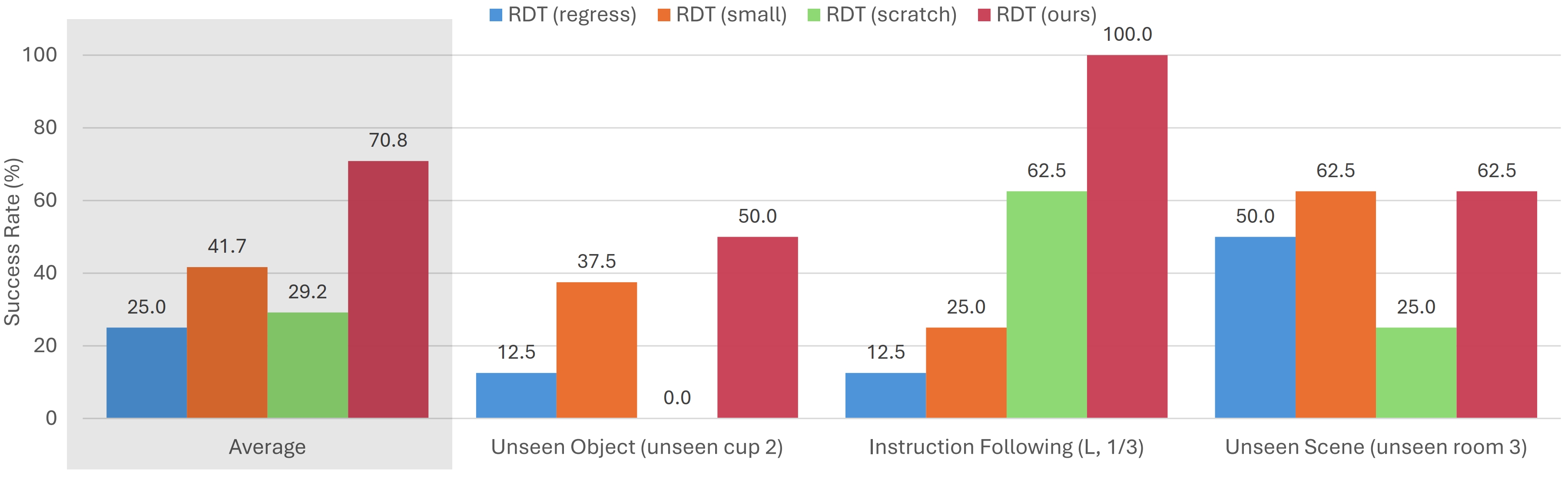 Results show that all components are crucial for the success of RDT.
Results show that all components are crucial for the success of RDT.
@article{liu2024rdt,
title={RDT-1B: a Diffusion Foundation Model for Bimanual Manipulation},
author={Liu, Songming and Wu, Lingxuan and Li, Bangguo and Tan, Hengkai and Chen, Huayu and Wang, Zhengyi and Xu, Ke and Su, Hang and Zhu, Jun},
journal={arXiv preprint arXiv:2410.07864},
year={2024}
}